



Your IDP/SSO automates 30% of provisioning. The other 70% — non-SSO apps, department-owned tools, shadow IT — runs on email, Slack reminders, and tribal knowledge. This is the anatomy of why that breaks at scale.
If you ask most enterprise IT teams how long it takes to provision a new user, the answer is somewhere between "30 minutes if everything goes perfectly" and "a week if it doesn't."
The reality is closer to the latter.
Not because IT teams are slow. Not because the systems are particularly complicated. But because provisioning at 300+ employees isn't a technical problem—it's a coordination problem. And coordination problems don't scale linearly.
When your company had 50 people, one IT admin could handle onboarding in a Slack thread and a few clicks. At 500 people with 50 hires per quarter, that same approach creates a permanent backlog, inconsistent setups, and security gaps that auditors love to flag.
This article examines why manual provisioning breaks at mid-market scale, what that breakdown actually costs, and what functional provisioning looks like when you're too big for informal processes but too small for costly enterprise budgets. More importantly, it examines why the industry's standard approach to this problem—buy an IDP, integrate your SSO apps, automate what you can—only solves 30% of the problem while leaving 70% still manual.
What Manual Provisioning Actually Looks Like
Here's the typical mid-market provisioning workflow:
- HR creates a ticket (Jira, Monday.com, email) requesting onboarding + hardware + access
- IT reads the ticket and tries to figure out what this person actually needs
- IT emails the hiring manager to confirm app requirements
- IT provisions accounts manually across 10-50 different systems
- IT coordinates with department admins who control their own apps (Sales owns Salesforce, Marketing owns HubSpot, Design owns Figma)
- IT waits for responses from admins who are busy with their actual jobs
- IT follows up via Slack when things get forgotten
- IT manually adds the user to groups, assigns licenses, configures app-specific settings
- IT sends login credentials to the new hire (hopefully before their start date)
- IT manually updates tracking spreadsheets
One customer described it this way: "Onboarding takes a minimum 1 week per user because multiple departments are involved. No automatic notifications. IT has to remind and follow up manually."
Another: "30 minutes to 4-6 hours per user depending on role complexity. We do this 15-20 times per month."
But these high-level steps hide what actually happens hour by hour, email by email, across the days it takes to provision someone. Let's trace a real scenario.
Hour-by-Hour: What Actually Happens When You Provision Someone
Monday, 9:00 AM: Sarah from HR creates a Jira ticket: "New hire: Alex Chen, Software Engineer, Engineering department, starts next Monday, reports to Mike (VP Engineering)."
Monday, 10:30 AM: Tom in IT sees the ticket. He emails Mike: "Alex starts next week. What apps does he need?" Mike is in meetings all day.
Monday, 4:45 PM: Mike responds via Slack (not email, so there's no thread): "Standard engineering setup + AWS + GitHub + Figma for design reviews."
Tuesday, 9:15 AM: Tom provisions the easy stuff:
- Creates account in Azure AD (2 min)
- Assigns Microsoft 365 E3 license (1 min)
- Adds to "Engineering" group in AD (30 sec)
- Creates Slack account (1 min)
- Adds to engineering Slack channels (2 min)
Tuesday, 9:30 AM: Tom emails ops@company.com asking for AWS access. The ops team uses a ticketing system Tom doesn't have access to. He waits.
Tuesday, 11:00 AM: Tom messages the #design channel in Slack: "Need Figma access for Alex Chen starting Monday." The design lead is out sick. Nobody responds.
Tuesday, 2:00 PM: Tom gets an email from the ops team: "We need more details for AWS access. Which role? Which projects?" Tom emails Mike again. Mike is traveling.
Wednesday, 10:00 AM: Mike responds: "Standard developer role, both the Platform and API projects." Tom forwards this to ops.
Wednesday, 3:00 PM: Ops provisions AWS access. Doesn't notify Tom. Tom doesn't know it's done.
Thursday, 9:00 AM: Tom follows up in #design: "Still need Figma access for Alex starting Monday." Design lead is back but says: "We're at our seat limit. Need to request more licenses. Filing ticket with procurement."
Thursday, 2:00 PM: Tom realizes he forgot to provision GitHub. Creates account, but GitHub org has 15 different teams. Tom doesn't know which teams Alex should be in. Emails Mike again.
Friday, 11:00 AM: Mike responds: "Frontend, Platform, and API repos. Also needs admin on API repo for CI/CD."
Friday, 11:30 AM: Tom provisions GitHub access. Manually adds Alex to three teams. Manually configures repository permissions.
Friday, 3:00 PM: Tom double-checks: Azure AD ✓, M365 ✓, Slack ✓, AWS ✓ (he thinks), GitHub ✓, Figma ✗ (still waiting on licenses).
Monday (Alex's first day), 8:00 AM: Alex logs in. Has email, Slack, GitHub. AWS credentials haven't been sent. Figma still not provisioned. Alex messages IT: "I need AWS access and Figma."
Monday, 9:00 AM: Tom discovers AWS was provisioned but credentials were sent to Mike instead of Alex. Tom requests new credentials be sent to Alex. Takes 2 hours.
Monday, 2:00 PM: Design team notifies Tom: Figma licenses approved, can provision now. Tom provisions Figma. Alex has been unable to participate in design reviews all day.
Total elapsed time: 8 days (one business week). Total IT time: 3 hours spread across a week. Total coordination messages: 15+ emails and Slack messages. Alex's experience: Started work with 60% of needed tools, spent half of day one requesting access.
This is for one person. Now multiply by 50 hires per quarter.
The problem isn't the time per task. Each individual step is quick. The problem is coordination latency across asynchronous communication with 5-15 stakeholders who have other priorities.
This is what scales badly. Not the provisioning itself—the coordination required to provision.
What Happens When IT Guesses Wrong
The above scenario assumes IT eventually gets accurate requirements. Often they don't.
Scenario 1: Over-provisioning
Tom provisions Alex with "standard engineering access." This includes:
- All engineering Slack channels (including #security-incidents and #exec-engineering)
- Admin access to 3 GitHub repos Alex will never touch
- Full access to AWS production environment
- Access to Figma, Jira, Confluence, Datadog, PagerDuty
Alex actually needs about 60% of this. The rest creates:
- Security exposure (unnecessary access to sensitive channels)
- License waste ($200/month in unused tool licenses)
- Confusion for Alex (which tools are actually important?)
- Audit findings (why does a junior dev have prod admin?)
Scenario 2: Under-provisioning
Tom provisions Alex with what he thinks engineering needs. Alex starts work. Over the first two weeks, Alex submits six access request tickets:
- "Need access to Design system in Figma"
- "Need PagerDuty for on-call rotation"
- "Need admin access to API repo for deployments"
- "Need Datadog access to investigate performance issues"
- "Need access to #platform-architecture channel"
- "Need access to internal documentation in Notion"
Each ticket takes 1-3 days to process. Alex's productivity is blocked repeatedly during the critical first two weeks.
The impact: Alex spent 40% of week one and 20% of week two blocked waiting for access. Alex's manager is frustrated. Alex questions whether this is a well-run company. And IT spent more time fielding access requests than if they'd provisioned correctly upfront.
Both scenarios stem from the same root cause: IT doesn't have systematic knowledge of what each role needs. They're guessing based on tribal knowledge, and tribal knowledge is inconsistent.
The Multi-Instance Problem
Let's make the scenario more realistic for many mid-market companies: Alex doesn't just need one Slack account. The company has:
- Main corporate Slack workspace
- Separate Slack workspace for acquired subsidiary
- Engineering-specific Slack workspace
Alex needs to be in two of these. Tom doesn't know which two. The subsidiary Slack admin doesn't report to Tom.
Or: The company has three Microsoft 365 tenants (US, EU, and an acquired company that was never merged). Alex needs accounts in two of them. Provisioning must be coordinated across two separate IT teams.
Or: The company has two AWS accounts (production and development) managed by different teams with different access request processes.
One customer described this: "One person may have 3 Google Workspace accounts across different tenants. We cannot offboard comprehensively because we don't track which instances each person is in."
Multiply the coordination burden by the number of instances, and provisioning time goes from 3 hours to 6-8 hours. More importantly, the chance of missing something goes from 20% to 60%.
This is a structural problem. The question isn't "why is IT slow at provisioning." The question is "how would any team provision efficiently across 50 apps, 5-15 stakeholders, 3-5 system instances, and asynchronous communication?"
They wouldn't. Which is why manual provisioning breaks at scale.
The Math That Nobody Wants to Do
Let's calculate what manual provisioning actually costs a 800-person mid-market company:
Volume:
- 50 hires per quarter (conservative for growth stage)
- 200 hires per year
- Average 2 hours of IT time per hire (includes coordination, delays, rework)
- 400 hours per year just for provisioning
Cost:
- IT staff fully-loaded cost: ~$100-150K
- Hourly cost: ~$60-75
- 400 hours × $65 = $26,000 in direct IT labor
But that's just provisioning time. What about the coordination overhead?
Hidden coordination costs:
- Hiring manager time answering access questions: 30 min per hire × 200 = 100 hours @ $75/hr = $7,500
- Department admin time provisioning apps they control: 20 min per hire × 200 = 67 hours @ $65/hr = $4,355
- IT time fielding access request tickets from under-provisioned users: 20% of hires × 3 tickets × 30 min = 60 hours @ $65/hr = $3,900
- HR time tracking provisioning completion: 15 min per hire × 200 = 50 hours @ $55/hr = $2,750
Productivity loss costs:
- New hire waiting 3-5 days for complete access: Average 1 day productivity loss × $500/day × 200 hires = $100,000
- Under-provisioned users blocked waiting for access during first month: 20% of hires × 2 days blocked × $500/day = $20,000
Security and compliance costs:
- Over-provisioned access creating audit findings: 2 findings per audit × 40 hours remediation @ $75/hr = $6,000/year
- Inconsistent provisioning requiring manual access reviews: 20 hours per quarter × 4 quarters @ $65/hr = $5,200/year
Total annual cost: $175,705
Now let's look at what IT isn't doing while spending 400 hours on manual provisioning:
Opportunity costs:
- Security improvements (implementing MFA on remaining apps, hardening configurations)
- Infrastructure automation (IaC, CI/CD improvements)
- Cost optimization (rightsizing cloud resources, eliminating unused licenses)
- Strategic projects (implementing new tools, improving developer productivity)
An IT team of 8 people has roughly 16,000 productive hours per year (accounting for meetings, email, PTO, etc.). Spending 400 hours on manual provisioning means 2.5% of total IT capacity goes to repetitive coordination work.
But remember: This is just new hire provisioning. Add in:
- Offboarding (150 users/year × 2 hours = 300 hours)
- Role changes (50 users/year × 1.5 hours = 75 hours)
- Access requests (500 tickets/year × 30 min = 250 hours)
- Contractor offboarding (100 users/year × 1 hour = 100 hours)
Total identity lifecycle management: 1,125 hours per year = 7% of total IT capacity.
For a team of 8 people, that's more than half of one full-time employee doing nothing but identity lifecycle management. Except it's actually distributed across the entire team, which means everyone is context-switching, nobody owns it, and it never gets better.
That's the real cost of manual provisioning: It's expensive, it scales badly, and it prevents IT from doing anything strategic.
The Cost Accumulation Over Time
Let's project this forward for a growing mid-market company:
Year 1 (500 employees):
- 200 hires
- 1,125 hours identity lifecycle work
- $175K total cost
Year 2 (650 employees, 30% growth):
- 260 hires
- 1,463 hours identity lifecycle work
- $227K total cost
Year 3 (850 employees, 30% growth):
- 340 hires
- 1,913 hours identity lifecycle work
- $297K total cost
Year 4 (1,100 employees, 30% growth):
- 440 hires
- 2,475 hours identity lifecycle work
- $385K total cost
5-year total: $1,389,000
This assumes linear scaling. In reality, coordination overhead scales worse than linearly. At 1,100 employees, you have more departments, more system instances, more approval layers, more exceptions to standard processes.
The company that doesn't fix provisioning in year one will spend over $1.3M in the next five years on manual coordination work. That's the cost of not systematizing identity lifecycle management.
And this still doesn't count the security incidents, audit failures, or productivity loss that stems from inconsistent access management.
Why It Breaks at Enterprise Scale
Small companies can handle provisioning informally. Large enterprises have invested in automation. Mid-market sits in the painful middle: high enough volume to hurt, complex enough to matter, but often under-prioritized versus product and revenue initiatives.
Here's what breaks:
1. Tribal Knowledge Becomes a Single Point of Failure
At 50 employees, one IT person knows what everyone needs. At 500 employees, that knowledge is scattered across multiple people, departments, and spreadsheets that nobody updates.
Customer quote: "IT knows which apps people need based on experience - not documented. Information sits in spreadsheets or with individuals."
What tribal knowledge looks like in practice:
Tom in IT knows:
- Sales reps need Salesforce, HubSpot, LinkedIn Sales Navigator, ZoomInfo
- Customer Success needs Salesforce, Zendesk, Calendly, Loom
- Engineers need GitHub, AWS, Datadog, Jira, Figma
- Finance needs NetSuite, Bill.com, Expensify
But Tom doesn't know:
- Which Salesforce license type (Sales Cloud vs Service Cloud)
- Which Salesforce role (Sales Rep vs Sales Manager has different access)
- Which GitHub teams (Frontend, Backend, DevOps, Security)
- Which AWS IAM groups (Developers, Senior Developers, DevOps)
- Whether this specific hire needs special access (sometimes sales reps need Zendesk too for support escalations)
Tom asks the hiring manager. The hiring manager says "standard access." What's standard? The hiring manager doesn't actually know—they just know their people have access to the tools they need. They've never enumerated it.
So Tom looks at what other people in that role have. But different people have different access because they were provisioned at different times by different IT people using different assumptions.
Result: Tom makes his best guess. Provisions 80% of what's needed. The new hire requests the missing 20% via tickets over the first two weeks.
Now multiply this scenario across 50 hires per quarter. The accumulated inconsistency is massive. No two people in the same role have identical access. Over-provisioning and under-provisioning coexist in the same cohort.
The symptoms:
- New IT staff take 2-4 weeks to learn manual processes and get admin access to 50+ apps
- Different new hires get different setups depending on who handles onboarding
- Vacation or sick days block provisioning entirely (only Tom knows the GitHub process)
- When someone leaves, their knowledge leaves with them
- Cannot create documentation because the process isn't standardized
- Training consists of shadowing and asking questions
The impact:
- Cannot onboard new IT staff quickly
- Cannot scale the IT team (adding more people doesn't help if they take a month to be productive)
- Quality varies significantly (audit finding: "Inconsistent access controls")
- Knowledge concentration creates risk (what happens if Tom leaves?)
One customer described new IT onboarding: "New IT staff need admin access to every app to provision users - takes weeks to get all access and learn manual processes. Without proper onboarding, they spend weeks requesting admin access one app at a time."
This isn't a training problem. It's a systems problem. When provisioning logic lives in people's heads instead of documented workflows enforced by systems, you cannot scale. Every new IT hire learns a slightly different version of "how we do things," and the variance compounds.
At enterprise scale, this problem gets solved through documentation, process automation, and role-based access control (RBAC) systems. At startup scale, the problem doesn't exist yet—one person can hold it all in their head.
Mid-market has neither advantage: too complex for one person to know everything, too small to have invested in systematic RBAC. You're scaling chaos.
2. Multi-Department Coordination Creates Delays
At mid-market scale, apps are owned by different departments:
- Sales controls Salesforce
- Marketing controls HubSpot and SEMrush
- Design controls Figma
- Engineering controls GitHub and AWS
- Finance controls NetSuite
- HR controls BambooHR
- Operations controls Jira and Confluence
Customer quote: "Departments own their own apps (Zoom, Canva, SEMrush) → IT does not have central access. Communication happens through Slack or email, not through a structured workflow."
Why departments own apps instead of IT:
This isn't poor organizational design. It's practical necessity:
- Sales needs to provision Salesforce daily → giving IT this responsibility would create bottleneck
- Marketing needs to control SEMrush seats → marketing budget pays for it
- Design needs to manage Figma → they need to control who can edit the design system
- Engineering needs to control GitHub → security requires engineer review of repo access
Distributed ownership is fine when users already exist. It's disastrous for new hire onboarding when coordination is required across 5-15 stakeholders.
The coordination burden:
For each new hire, IT must:
- Determine which apps are needed
- Identify who owns each app
- Email/Slack each owner requesting provisioning
- Wait for responses (department admins have other jobs)
- Follow up when requests get lost
- Verify provisioning was completed
- Notify new hire of access
- Track completion in a spreadsheet
The timeline:
- Day 0: Hire starts, IT sends requests to 8 department app owners
- Day 1: 3 admins respond and provision immediately
- Day 2: IT follows up with 5 non-responders via Slack
- Day 3: 3 more admins respond. 2 are out of office.
- Day 4: IT escalates to department heads for the missing 2
- Day 5: Remaining provisioning completed
Result: 1+ week onboarding delays for a process that should take hours. The bottleneck isn't technical capability—it's asynchronous human coordination across organizational silos.
No SLA enforcement:
When IT controls all provisioning, they can commit to SLAs (new hires provisioned by 8 AM on start date). When 8 departments control provisioning, IT cannot commit to anything. They can send requests. They cannot guarantee responses.
This creates problems:
- New hires start work missing critical tools
- Hiring managers complain to IT (but IT doesn't control the bottleneck)
- IT looks ineffective (despite doing their part)
- Employee experience suffers
- No accountability
No audit trail:
When provisioning happens via Slack messages and email:
- No central log of who requested what
- No record of who approved access
- No proof of when provisioning was completed
- Cannot demonstrate compliance controls
- Cannot answer auditor questions like "who authorized this Sales Engineer to have admin access to Salesforce?"
Auditors expect to see:
- Access request with business justification
- Manager approval
- Provisioning action
- Timestamp for each step
What mid-market companies actually have:
- Slack message: "Need to add Alex to Salesforce"
- Response: "Done"
That's not an audit trail. That's evidence that provisioning happened, but with no context, no approval, no business justification, no accountability.
The architectural problem:
Centralized access control requires centralized authority. Decentralized ownership requires decentralized provisioning. Mid-market companies have decentralized ownership but try to coordinate centrally through IT.
You cannot coordinate decentralized provisioning with email and Slack at scale. You need orchestration—workflows that route tasks to appropriate owners, enforce SLAs, create audit trails, and provide central visibility without requiring central execution.
But most mid-market companies don't have orchestration platforms. They have ticketing systems designed for break-fix support, not for cross-functional workflows.
3. No Standardization Means Every Hire Is Different
Mid-market companies rarely have documented "role bundles" or "birthright access" policies. IT figures it out each time based on the specific hire, the manager's description, and what similar people were given previously.
Customer quote: "No birthright apps or department-based provisioning - IT figures it out each time based on asking the manager."
What this looks like:
Manager submits onboarding request: "New hire: Sarah Jones, Account Executive, Sales."
IT's questions:
- What's an Account Executive vs a Sales Development Rep vs an Inside Sales Rep?
- Do AEs need the same access as SDRs?
- Does Sarah need Salesforce admin or just user access?
- Does she need HubSpot (some AEs use it, some don't)?
- Does she need ZoomInfo (only if she does prospecting)?
- Does she need Gong (only if we're recording sales calls)?
- Does she need Slack channel access to #sales-west or #sales-east or both?
IT emails the manager. Manager responds: "Give her what other AEs have."
But other AEs don't have uniform access. They've accumulated different tools over time based on:
- When they were hired (company had different tools 2 years ago)
- Who provisioned them (different IT people made different choices)
- What they requested later (some have tools others don't)
- Changes in role (promoted AEs kept old tools plus got new ones)
So IT looks at 3 different AEs and sees 3 different access patterns. IT makes a judgment call about what seems "standard."
Result: Sarah starts work with 80% of what she needs, 20% of what she doesn't need, and submits 2-3 access requests during her first week when she realizes what's missing.
This plays out 200 times per year. Inconsistent provisioning across 200 hires creates massive variance in access patterns, making it impossible to audit, impossible to enforce least privilege, and impossible to optimize licenses.
Why birthright access matters:
Birthright access = "If you are X role in Y department, you automatically get access to these specific apps with these specific permissions."
Without birthright access:
- Every hire is a special case requiring investigation
- No consistency across cohorts
- Cannot enforce policy systematically
- Cannot automate (automation requires rules, rules require standardization)
- Cannot audit effectively (auditors ask "why does this person have admin access" and the answer is "because Tom thought they needed it")
With birthright access:
- Onboarding becomes deterministic: Role → Access
- Consistency across cohorts
- Policy is explicit and auditable
- Automation becomes possible
- Exceptions require justification (and are tracked)
The documentation problem:
To implement birthright access, you need to document:
- All roles in the organization (Sales Rep, Account Executive, VP Sales, etc.)
- All apps each role needs
- All permission levels each role needs per app
- All variations (does "Sales Engineer" need different access than "Account Executive"?)
For a 500-person company with 20 departments and 5-10 roles per department, that's 100-200 role definitions. Each role might need access to 10-30 apps. That's 1,000-6,000 role-app-permission mappings to document.
Nobody has time to document this from scratch. So it stays in people's heads, provisioning stays ad-hoc, and inconsistency persists.
This is why discovery matters: you cannot document birthright access by interviewing people. You document it by observing what access people actually have today, identifying patterns, and codifying those patterns as policy.
4. The 70/30 Coverage Problem
Most mid-market identity providers (Okta, Azure AD) cover 30-40% of apps. The other 60-70% have no SSO integration, no API, or live on-premises.
Customer quote: "Entra and Active Directory only handle apps that support Entra integration or SSO. This covers about 30% of our total apps. For the other 70%, the permissions team has no visibility."
What the 30% includes:
Your IDP (Okta, Azure AD, Google Workspace) can provision:
- Email and productivity suite (M365, Google Workspace)
- Core SSO-enabled apps (Salesforce, Slack, GitHub if configured properly)
- Cloud infrastructure (Azure, AWS if SAML/SCIM enabled)
- HR tools (BambooHR, Workday if integrated)
For these apps, you can:
- Auto-provision when user is created
- Auto-deprovision when user is disabled
- Sync group membership
- Enforce MFA
- Get audit logs
What the 70% includes:
Apps that aren't in your IDP:
- Legacy on-prem systems (ERP, databases, custom apps)
- Department-owned SaaS tools without SSO (Canva, SEMrush, various marketing tools)
- Apps with SSO but no SCIM (have SSO, cannot auto-provision)
- Shadow IT (tools purchased on credit cards, free trials)
- Contractor-specific access (temporary tools, project-specific apps)
- Regional tools (APAC uses different tools than US)
- Acquisition tools (bought company's apps not yet integrated)
For these apps, you must:
- Manually provision during onboarding
- Manually track who has access
- Manually deprovision during offboarding
- Manually review access for audits
- Hope you don't forget any during offboarding
The math:
500 person company, average 30 apps per employee (conservative), 15,000 total user-app relationships.
If IDP covers 30%:
- 4,500 relationships automated
- 10,500 relationships manual
For provisioning:
- 200 new hires per year
- 30 apps per hire
- 6,000 provisioning actions needed
- 30% automated = 1,800 automatic
- 70% manual = 4,200 manual
For offboarding:
- 150 terminations per year
- 30 apps per person
- 4,500 deprovisioning actions needed
- 30% automated = 1,350 automatic
- 70% manual = 3,150 manual
Even if your IDP is perfectly configured (most aren't), you're still doing the majority of provisioning and deprovisioning work manually.
Why the 70% exists:
Legacy systems: Mid-market companies have accumulated 10-20 years of systems. The ERP purchased in 2010 doesn't have SSO or APIs. Replacing it would cost millions. So it stays, and provisioning remains manual.
Department-owned tools: Marketing needs 15 different tools (SEMrush, Ahrefs, Canva, various ad platforms). Some have SSO, most don't. These were purchased on marketing budget, not vetted by IT, never integrated with IDP.
Cost constraints: Enabling SCIM often requires enterprise tier subscriptions. A 500-person company might not want to pay enterprise pricing on every tool just to get auto-provisioning.
Technical debt: Engineering has 10 custom internal tools built in-house. These have ad-hoc authentication (database users, API keys, manual access grants). Nobody's had time to integrate them with the IDP.
Shadow IT: Employees sign up for tools with company email. IT doesn't know these exist until someone asks for provisioning or (more commonly) until the employee leaves and IT tries to offboard comprehensively.
The impact:
This isn't just "some apps are manual." The 70% creates:
- Incomplete onboarding: New hires wait days for 70% of their tools
- Incomplete offboarding: Ex-employees retain access to 70% of their apps (security risk)
- No visibility: Cannot answer "who has access to what" for 70% of apps
- Manual access reviews: Must pull user lists manually from 70% of apps for compliance
- License waste: Cannot see unused licenses in 70% of apps
- Security blind spots: Cannot enforce MFA, cannot see login activity, cannot detect suspicious access for 70% of apps
You cannot solve provisioning with just an IDP. You need visibility into all apps (not just SSO), orchestration for manual provisioning workflows, and audit trails for apps that cannot be automated.
This is the fundamental mistake most companies make: they think "buy an IDP" solves provisioning. It doesn't. It solves 30% of provisioning while leaving 70% exactly as manual as before, except now you've spent $50K-200K per year on the IDP.
5. Spreadsheet-Based Rules That Cannot Scale
Many mid-market companies have documented access rules in spreadsheets. These started as simple mappings and evolved into thousands of conditional rules that nobody can fully understand.
Customer quote: "If job title = X AND department = Y → give access to App Z. These rules cover thousands of lines and are updated often. Rebuilding them manually in any new system would be painful, slow, and risky."
What the spreadsheet looks like:
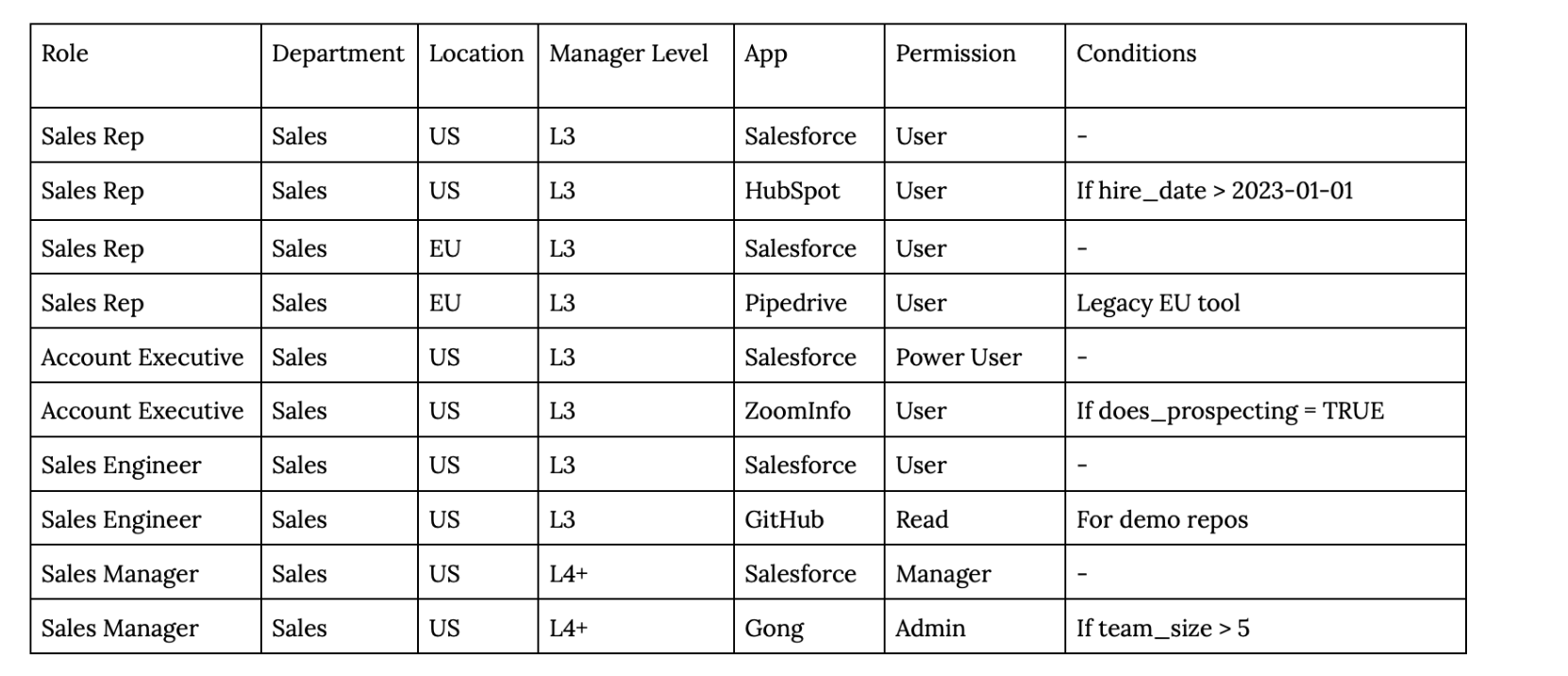
Now extend this across 100 roles, 50 apps, multiple regions, multiple conditions. The spreadsheet grows to 500-2,000 rows.
What makes it unmaintainable:
Conditional logic: Rules aren't just "if role = X then app = Y." They're "if role = X AND department = Y AND location = Z AND hire date > 2023 AND manager level > L4 THEN app = Y UNLESS condition C."
Constant changes:
- Company adopts new tool → add 100 rows (one per role that needs it)
- Company sunsets old tool → delete 100 rows (but which ones?)
- Role definitions change → update 50 rows
- Regional expansion → duplicate rules with location modifier
No version control: Spreadsheet lives on SharePoint or Google Drive. Multiple people edit it. No history of what changed, when, or why.
Tribal knowledge: The spreadsheet documents the rules, but understanding why rules exist lives in people's heads. "Sales Engineers get GitHub read access for demo repos" makes sense to the person who wrote it. Six months later, nobody remembers why this is necessary or whether it's still needed.
No validation: When you edit the spreadsheet, nothing checks whether the rule conflicts with other rules or whether the app even exists anymore.
Single point of failure: Usually 1-2 people understand the spreadsheet well enough to edit it safely. When they're unavailable, nobody touches it for fear of breaking something.
The impact:
Cannot automate: You could theoretically build a provisioning system that reads this spreadsheet and provisions accordingly. But:
- Conditional logic is too complex to parse reliably
- Rules conflict or have ambiguous precedence
- No validation means errors accumulate
- The provisioning system becomes as fragile as the spreadsheet
Rules break: Employee gets promoted from L3 to L4. The spreadsheet says L4+ gets admin access to Gong. But nobody updates the spreadsheet for 6 months. When the next L4 is hired, they don't get Gong admin because the rule wasn't applied correctly. Over time, reality diverges from the spreadsheet.
Cannot onboard new IT staff: New IT hire looks at the spreadsheet. Sees 2,000 rows. Asks: "How do I know which rules to apply for this specific hire?" Answer: "You have to understand the logic." But the logic isn't documented. It's learned through experience.
Audit nightmares: Auditor asks: "Why does this person have admin access to this app?" IT looks at the spreadsheet. Finds three potentially applicable rules. Not sure which one was actually used (or if the person was provisioned before the spreadsheet existed, or if it was an exception granted via email).
The path dependency problem:
These spreadsheets exist because at some point in the company's history, someone tried to bring order to chaos by documenting access patterns. This was a good impulse. But spreadsheets cannot scale to:
- Thousands of conditional rules
- Multiple editors
- Continuous change
- Complex conditional logic
- Audit requirements
The spreadsheet represents accumulated institutional knowledge. Abandoning it means starting from scratch. Keeping it means perpetuating an unmaintainable system.
This is why many mid-market companies stay stuck: the pain of living with spreadsheet-based rules is bad, but the pain of rebuilding from scratch seems worse.
The solution isn't to abandon the spreadsheet—it's to extract the knowledge from the spreadsheet systematically (through discovery of actual access patterns) and codify it in a system that can enforce rules programmatically.
6. No HR-to-IT Synchronization
HR systems (Workday, BambooHR, ADP) and identity systems don't sync automatically. Employee data lives in multiple places with different values, creating delays and errors in every lifecycle event.
Customer quote: "When HR is not synced with identity: access lingers after offboarding, new joiners don't get apps on time, org/role changes don't update permissions. HR has one department value, IDP has another - this breaks onboarding conditions."
The architecture problem:
Most mid-market companies have:
- HR system: Source of truth for employee data (hire date, termination date, job title, department, manager, location)
- Identity provider: Source of truth for accounts and access (Azure AD, Okta)
- Apps: Each has its own user database
These systems don't sync. Changes in HR don't automatically propagate to IDP or apps.
What breaks:
New hire onboarding:
- Day -7: Manager submits requisition in HR system
- Day -1: HR creates employee record (start date = Monday)
- Day 0 (Monday): New hire starts
- Day 0, 9 AM: HR emails IT: "Alex starts today, needs provisioning"
- Day 0, 10 AM: IT begins provisioning
The new hire shows up at 9 AM expecting accounts to exist. They don't. IT didn't know the hire was starting because HR didn't notify IT until the day of.
Why didn't HR notify earlier? Because HR's workflow is to complete hiring paperwork immediately before start date. IT's workflow is to provision accounts 1-2 days before start. These workflows don't integrate.
Offboarding:
- Day 0: Employee is terminated (voluntary or involuntary)
- Day 0: Manager notifies HR
- Day 1: HR processes termination paperwork
- Day 2: HR updates HRIS with termination date
- Day 2: HR emails IT: "Please offboard Alex"
- Day 2-5: IT begins deprovisioning apps
The problem: The employee had active access for 2 days after termination. If this was an involuntary termination (fired for cause), that's 2 days of security exposure.
Customer quote: "HR often delays updating termination data. IT must disable Slack immediately before HR even updates the system. Minutes matter for high-risk terminations."
Role changes:
- Day 0: Employee promoted from Sales Rep to Sales Manager
- Day 0: Manager notifies HR
- Day 1-5: HR processes role change in HRIS
- Day 5: HR notifies IT via email
- Day 5-10: IT determines what access should change (no documented policy)
- Day 10: IT provisions new access (Gong admin, Salesforce manager license)
- Day 10: IT forgets to remove old access (keeps sales rep permissions)
Result: The employee now has accumulated permissions from both roles (privilege creep). Will likely stay that way until next access review (if ever).
The attribute mismatch problem:
HR and IDP store the same data differently:
- Department in HRIS: "Sales - Enterprise"
- Department in Azure AD: "Sales"
- Department in Salesforce: "Ent Sales"
Access rule says: "If department = 'Sales - Enterprise' then give Salesforce Power User."
But IDP shows department = "Sales" so rule doesn't match. User doesn't get access. Manager complains. IT manually provisions. But now there's no audit trail of why this exception was granted.
Or worse:
HR changes department values to follow new org structure:
- Old: "Engineering - Platform"
- New: "Product Engineering - Platform Team"
All access rules break because they're looking for "Engineering - Platform." IT doesn't know HR changed the taxonomy until provisioning starts failing.
The impact:
Delays: Every lifecycle event (hire, fire, role change) requires human-in-the-loop coordination between HR and IT. Minimum 24-48 hour delay.
Errors: Manual data entry between systems. Typos. Copy-paste errors. Attributes that don't match.
Incomplete automation: Even if you automate parts of provisioning, if HR data doesn't flow automatically to provisioning systems, you still need manual triggers.
Audit problems: Cannot prove that access was provisioned/deprovisioned based on authoritative HR data. Cannot demonstrate that only active employees have access.
The integration problem:
Integrating HR and identity systems isn't technically difficult. Most modern HR systems have APIs. Most IDPs can consume HR data.
The problem is organizational: HR and IT are separate departments with separate budgets, priorities, and systems. Nobody owns the integration. HR bought their HRIS for HR workflows (payroll, benefits, org charts). IT bought their IDP for identity workflows (SSO, MFA, groups).
Neither system was designed to feed the other. Building the integration requires:
- Both teams agreeing it's a priority
- Engineering resources to build and maintain the integration
- Data governance (who owns employee data? what happens when they conflict?)
- Change management (what happens when HR changes their taxonomy?)
At mid-market scale, this often doesn't happen. HR and IT coordinate manually via email and tickets.
This is why lifecycle automation fails: You cannot automate provisioning based on employee data if employee data doesn't flow automatically into provisioning systems.
The Deprovisioning Problem: Provisioning in Reverse, Except Worse
If provisioning is hard at mid-market scale, deprovisioning is harder. All the same coordination problems exist, plus you're working backwards from incomplete information with security stakes that are much higher.
Orphaned Accounts at Scale
When someone leaves the company, their account should be removed from every system. In practice, this rarely happens comprehensively.
Customer quote: "Okta disablement works, but users still exist in Azure, AWS, and other systems. Ex-employees still have active access in many apps. Auditors flag these accounts quarterly."
What actually happens:
- Day 0: Alex leaves the company (last day)
- Day 1: HR updates HRIS with termination date
- Day 1: IT disables Alex's account in Azure AD
- Day 1: SSO stops working for Alex (cannot log into Okta/Azure-integrated apps)
But:
- Alex still has an active account in Salesforce (not disabled, just cannot log in via SSO)
- Alex still has an active account in AWS (separate identity system)
- Alex still has an active account in GitHub (separate identity system)
- Alex still has accounts in 20 non-SSO apps (Canva, SEMrush, various department tools)
- Alex's licenses are still assigned
- Alex appears as "active user" in admin panels
Why this matters:
Security risk: If Alex had direct credentials (not SSO-only), the account is still accessible. If SSO eventually breaks or is bypassed, the account can be used.
License waste: Alex's licenses cost $500-2,000 per year depending on apps. They're still assigned. Still being paid for.
Audit findings: External auditors (SOC 2, ISO 27001) flag every terminated employee with active accounts. This is a control failure. One customer reported: "Auditors ask: Why do terminated users still have visible accounts? This leads to compliance failures."
Volume math:
500 person company, 150 terminations per year, 30 apps per employee.
If deprovisioning covers 30% (SSO apps):
- 1,350 accounts automatically disabled
- 3,150 accounts require manual deprovisioning
In reality, manual deprovisioning doesn't happen systematically. IT focuses on high-value apps (Salesforce, GitHub, AWS) and forgets low-value apps (Canva, various free trials, department tools).
Accumulation:
- Year 1: 150 terminations × 30 apps × 70% manual = 3,150 orphaned accounts
- Year 2: 3,150 + 3,150 = 6,300 orphaned accounts
- Year 3: 6,300 + 3,150 = 9,450 orphaned accounts
After 3 years, a 500-person company can easily have 9,000+ orphaned accounts across their app portfolio. That's 18 orphaned accounts per current employee on average.
These accounts:
- Consume licenses ($900K+ in wasted spend)
- Create security exposure (accounts that shouldn't exist are attack surface)
- Generate audit findings (repeated failures per quarter)
- Require manual cleanup (IT spending weeks cleaning up years of accumulated accounts)
Why cleanup doesn't happen:
IT knows orphaned accounts exist. But cleaning them up requires:
- Identifying every app (discovery problem)
- Pulling user lists from each app (manual work)
- Identifying which users are terminated (cross-reference with HRIS)
- Removing accounts one by one (manual work per app)
- Verifying removal (manual checks)
For 50+ apps, this is weeks of work. IT triages: "Do we spend 3 weeks cleaning up old accounts or do we focus on keeping the business running?"
They focus on keeping the business running. Cleanup gets perpetually deferred. Orphaned accounts accumulate.
The Offboarding Coordination Problem
Deprovisioning requires coordination across the same 5-15 stakeholders as provisioning, except now:
- It's time-sensitive (security exposure with every hour of delay)
- Information is incomplete (IT may not know all the apps the person had)
- Stakeholders are less responsive (person is gone, less urgency)
Customer quote: "Department admins control many apps → fragmentation. Must keep checking if someone left the org. Cleanup is manual and inconsistent."
What offboarding coordination looks like:
- Day 1: Alex leaves company, HR notifies IT
- Day 1: IT disables Alex in Azure AD and primary apps (Slack, email, Salesforce, GitHub)
- Day 1: IT sends email to 8 department app admins: "Alex left, please remove from your apps"
- Day 2: 2 admins respond and remove access
- Day 3: IT follows up with 6 non-responders
- Day 4: 3 more admins respond
- Day 5: IT escalates to department heads for remaining 3
- Day 7: Remaining removals completed
Result: Full offboarding takes 5-7 days. Alex had access to some apps for a week after leaving.
The information gap problem:
For provisioning, IT asks the manager what apps the person needs. For deprovisioning, IT should remove all apps the person had. But IT doesn't have a complete list of apps the person had.
Why? Because:
- Apps were provisioned over time by different people
- Some apps were never provisioned by IT (direct sign-ups, shadow IT)
- Department-owned apps were provisioned by departments (IT wasn't involved)
- No central system tracks all apps per user
So IT works from:
- IDP group memberships (shows some apps)
- Email searches ("what apps did we provision for Alex?")
- Manager's memory ("what apps did Alex use?")
- Department admin questions ("did Alex have access to your apps?")
This is incomplete. Apps get forgotten. Access remains.
Emergency Offboarding: When Minutes Matter
Voluntary terminations can be handled over days. Involuntary terminations need to happen in minutes.
Customer quote: "IT must disable Slack immediately before HR even updates the system. We're informed minutes before or during the termination meeting. Manual rush work under high stress."
The scenario:
- 10:00 AM: CEO decides to terminate Alex (cause: suspected data theft)
- 10:05 AM: CEO messages IT director on personal phone: "Disable Alex's access NOW"
- 10:05 AM: IT director doesn't have access to every system from phone
- 10:06 AM: IT director calls IT team: "Emergency offboarding for Alex"
- 10:10 AM: IT team begins disabling accounts
- 10:10 AM: Azure AD disabled ✓
- 10:12 AM: Slack disabled ✓
- 10:15 AM: Email disabled ✓
- 10:18 AM: Salesforce disabled ✓
- 10:20 AM: GitHub access removed ✓
- 10:25 AM: AWS access removed ✓
- 10:30 AM: IT realizes Alex had admin access to production database
- 10:35 AM: Database access removed ✓
Security window: 30 minutes of administrator access to production systems after termination decision. Plenty of time to exfiltrate data, delete databases, create backdoors.
The problem:
Emergency offboarding requires:
- Immediate notification (no 24-hour HR processing)
- Comprehensive app list (know every system the person can access)
- Fast execution (disable everything in minutes, not hours)
- No coordination delays (cannot wait for department admins)
Mid-market companies rarely have this capability. They have:
- Delayed notification (HR processes first, then notifies IT)
- Incomplete app lists (nobody knows every system)
- Serial execution (must log into each app separately)
- Coordination dependencies (some apps controlled by departments)
The "kill switch" that doesn't exist:
IT wants: "Click one button, everything gets disabled immediately."
Reality: No such button exists. Must disable:
- Azure AD (2 minutes)
- Salesforce (3 minutes)
- AWS (5 minutes)
- GitHub (3 minutes)
- Slack (2 minutes)
- Email (2 minutes)
- VPN (2 minutes)
- 15 department-owned apps (message admins, wait for responses)
Even with perfect execution, 30-60 minutes minimum for comprehensive offboarding.
The audit trail problem:
After emergency offboarding:
- Which accounts were disabled?
- In what order?
- Who performed each action?
- Were any missed?
- Can we prove comprehensive removal?
With manual execution across 50 apps by 3 different IT staff, the audit trail is reconstructed after the fact from memory and system logs.
Auditors don't love this.
Data Transfer: The Forgotten Step
Offboarding isn't just removing access. It's transferring data ownership so business continuity isn't disrupted.
Customer quote: "Forward emails, transfer Google Drive files, transfer ownership - all manual. Need to delegate mailbox to manager. This causes delays and data loss."
What needs to be transferred:
- Email: Forward Alex's email to manager, or give manager delegate access
- Drive/OneDrive: Transfer file ownership to manager
- Shared drives: Remove Alex from drive sharing, update permissions
- Calendar: Transfer meeting ownership, update recurring meetings
- Slack: Transfer channel ownership (if Alex owned channels)
- GitHub: Transfer repo ownership (if Alex owned repos)
- Documents: Transfer ownership in Google Docs, Confluence, Notion
- Projects: Reassign Jira tickets, transfer project ownership
How this actually happens:
- Day 1: Alex leaves
- Day 1-3: IT focuses on disabling access
- Day 4: Manager realizes they cannot access Alex's files
- Day 4: Manager emails IT: "I need Alex's files"
- Day 4: IT asks: "Which files?"
- Day 4: Manager: "All of them"
- Day 4: IT: "We don't have a list of Alex's files"
- Day 5: IT and manager manually transfer files one by one
- Day 10: Still finding files that need transfer
The impact:
Productivity loss: Manager and team blocked waiting for data transfer. Critical files inaccessible. Deals delayed. Projects blocked.
Data loss: Some files never get transferred because nobody knows they exist. Tribal knowledge lost when Alex left.
Manual coordination: IT and manager spend hours coordinating data transfer. This is time-intensive and error-prone.
No company has truly automated this. File ownership transfer is complex:
- Which files should transfer? (work files vs personal files)
- Who should receive files? (manager, team members, multiple people)
- What about shared files? (don't transfer, just update permissions)
- What about files that are already in shared drives? (leave them alone)
These decisions require human judgment. But mid-market companies don't have systematic processes for making these decisions, so data transfer happens ad-hoc under time pressure.
The Role Change Problem: Movement Without Visibility
Onboarding and offboarding are visible events. Role changes are invisible until they cause problems.
Customer quote: "When employees change teams, old access often remains. No automated revocation or updating of permissions. This creates over-privileged users and license waste."
Privilege Creep at Mid-Market Scale
The scenario:
Year 1: Sarah hired as Sales Rep
- Given: Salesforce, HubSpot, LinkedIn Sales Navigator, Gong
- License cost: $400/month
Year 2: Sarah promoted to Sales Manager
- Given: Salesforce admin, Gong admin, team dashboard access
- Old access: Not removed
- New license cost: $600/month (kept old + added new)
- Total Sarah licenses: $1,000/month
Year 3: Sarah moved to Customer Success leadership
- Given: Zendesk admin, Intercom, Gainsight, team tools
- Old access: Not removed (IT doesn't know Sarah left sales)
- New license cost: $500/month
- Total Sarah licenses: $1,500/month
Year 4: Sarah promoted to VP of Customer Experience
- Given: Executive dashboard access, analytics tools, budget tools
- Old access: Not removed
- New license cost: $300/month
- Total Sarah licenses: $1,800/month
After 4 years, Sarah has accumulated access from 4 different roles. She only needs her current VP access. The rest is:
- Security exposure (why does a VP have Salesforce admin?)
- License waste ($1,500/month in unnecessary licenses)
- Audit findings (least privilege violations)
This isn't malicious. This is organizational amnesia at scale. Nobody tracks what access was provisioned historically. Role changes don't trigger access reviews. Access accumulates indefinitely.
Why Role Changes Don't Trigger Access Updates
The visibility problem: HR knows Sarah changed roles. IT doesn't know what access Sarah had in her old role, what access she needs in her new role, or what should be removed.
The priority problem: New hire onboarding is high priority (person starting, needs tools). Role changes are low priority (person already working, currently has access).
The manual burden: Reviewing and updating access for role changes requires:
- Identifying what the person currently has (pull from 50 apps)
- Identifying what they should have in new role (no documentation exists)
- Identifying what to remove (compare current vs should-have)
- Coordinating removal across department admins
- Provisioning new access
- Verifying changes
This takes 2-3 hours per role change. At 50 role changes per quarter, that's 150 hours per quarter = 600 hours per year.
IT triages: "Do we spend 600 hours per year managing role change access, or do we let access accumulate and deal with it during access reviews?"
They deal with it during access reviews (which are also manual and often don't happen comprehensively).
The Volume Problem
Mid-market companies have high internal mobility. This is good for career development. It's bad for access management.
Volume math:
- 500 employees
- Average 2-year tenure before internal move
- 25% annual internal mobility = 125 role changes per year
Each person has 30 apps = 3,750 access changes needed per year (some access removed, some added, some unchanged)
Reality: <5% of these access changes happen proactively. The rest accumulate as privilege creep until forced remediation during audits.
The Promotion Problem
Promotions are particularly problematic because promoted employees need more access (new responsibilities) but also should lose old access (no longer doing individual contributor work).
Example: Sales Rep → Sales Manager
Should gain:
- Salesforce manager license (to manage team)
- Gong admin (to review team's calls)
- Team performance dashboards
- Budget tools
Should lose:
- Salesforce individual quota tracking
- LinkedIn Sales Navigator seat (not prospecting anymore)
- Individual sales tools
What actually happens:
IT provisions the "should gain" access (manager requests this explicitly). IT doesn't remove "should lose" access (nobody requests removal, IT doesn't know what to remove).
Result: Over-privileged managers who have both IC and manager access.
The Department Transfer Problem
When someone transfers departments, they need completely different apps. But who tracks this?
Example: Engineering → Sales
Should gain: Salesforce, HubSpot, sales enablement tools Should lose: GitHub, AWS, Datadog, engineering tools
What actually happens:
Manager requests Salesforce access for new sales rep. IT provisions. Nobody tells IT the person transferred from engineering. IT doesn't know to remove GitHub/AWS. Person keeps engineering access indefinitely.
Why this creates security problems:
Engineers have access to:
- Production systems
- Customer data
- Code repositories
- Infrastructure
When an engineer leaves engineering, they should lose this access immediately. But if IT doesn't know they left engineering (only knows they joined sales), the access remains.
After 3-4 years, the company has sales people with prod access, support people with GitHub admin, finance people with engineering tools. Nobody intended this. It accumulated through organizational amnesia.
The Contractor Problem: Temporary Access That Becomes Permanent
Mid-market companies typically have 50-200 active contractors at any time. These are 2-6 month engagements for specific projects. Their access should expire automatically when contracts end.
It doesn't.
No Automated Contract-End Offboarding
Customer quote: "Contractors join for 2-3 months. No automated offboarding at contract end. This creates leftover licenses and security risks."
The scenario:
Month 1: Contractor Alex hired for 3-month project
- Given: GitHub access, Slack, Figma, project tools
- Contract end date: 3 months
Month 4: Project ends, contract expires
- Contractor stops showing up to meetings
- Manager doesn't notify IT (assumes contract end handled automatically)
- IT doesn't track contractor end dates (different system from employee data)
- Access remains active
Month 6: Quarterly access review
- IT notices contractor still has access
- Manually removes access
- Realizes contractor kept access for 2 months after contract end
Why contract end dates don't trigger offboarding:
Separate systems: Contractor data lives in procurement/vendor management systems, not in HRIS. IT doesn't have visibility into contract end dates.
No integration: Even if IT can access contractor data, there's no automatic trigger from "contract ends" to "disable access."
Manual tracking: IT maintains spreadsheets of contractor access with end dates. But:
- Spreadsheet gets out of date
- End dates change (contracts extended)
- Nobody checks the spreadsheet daily
- When dates arrive, nobody is assigned to act
No ownership: Who is responsible for contractor offboarding?
- IT says: "We need HR to tell us when contractors leave"
- HR says: "Contractors aren't employees, procurement manages them"
- Procurement says: "We handle contracts, not IT access"
- Result: Nobody owns it
The Volume Problem
Math:
- 50 active contractors at any time
- Average 4-month contracts = 150 contractor offboardings per year
If 80% don't happen automatically:
- = 120 contractors per year keep access after contract end
- = 120 × 3 months average delay = 360 contractor-months of unnecessary access per year
Each contractor has 10 apps on average:
- = 3,600 app-months of unnecessary contractor access per year
Cost:
- 3,600 app-months × $50 average cost per app = $180,000 annual waste from contractor license accumulation alone
Security impact:
Contractors often have elevated access:
- External developers have GitHub/AWS access
- Consultants have sensitive business data access
- Designers have brand asset access
- Finance contractors have financial system access
When contractors keep access after engagement ends:
- Security exposure (no longer bound by contract, but still have access)
- Compliance violations (SOC 2 requires contractor access reviews)
- Audit findings (inactive contractors with active access)
Time-Bound Access That Isn't Enforced
Beyond contractors, mid-market companies frequently grant "temporary" access that becomes permanent.
Scenarios:
- "Give Alex access to Salesforce for 3 months while he covers Sarah's leave"
- "Give this consultant access to our analytics for 6 weeks for the market study"
- "Give the intern GitHub access for summer (3 months)"
What should happen:
- Access automatically expires after time period
- User notified before expiration
- Manager can extend if needed
What actually happens:
- IT provisions access
- Adds calendar reminder to revoke
- Calendar reminder gets dismissed
- Access stays indefinitely
Why time-bound access fails:
Manual enforcement: No system enforces time-bounds. IT must remember to revoke. Memory is unreliable at scale.
Distributed ownership: Time-bound access might be in apps controlled by departments. IT cannot revoke without coordination.
Unclear responsibility: When IT provisions temporary access for department request, who owns revocation? IT or department?
Accumulation:
- 50 temporary access grants per quarter
- 90% never revoked = 180 temporary accesses that became permanent per year
- Over 3 years = 540 accesses that should not exist
Each access:
- Costs money (license)
- Creates security exposure (unnecessary access)
- Violates least privilege
Temporary access should be the exception. At mid-market scale with manual enforcement, temporary becomes the norm.
Access Request Overload: Death By A Thousand Tickets
Beyond onboarding, offboarding, and role changes, mid-market IT teams handle hundreds of ad-hoc access requests per quarter.
Customer quote: "Most IT teams deal with: 'Add me to this app', 'Give me this license', 'Remove this user', 'My access stopped working' - this consumes many hours each week."
The Volume Problem
Typical mid-market access request volume:
- 500 employees × 0.5 access requests per month = 250 tickets per quarter
Request types:
- "Add me to X app" (30%)
- "Give me Y license/permission" (25%)
- "My access stopped working" (20%)
- "Remove Z from this app" (10%)
- "I need higher permissions" (10%)
- "This person left, why do they still have access?" (5%)
Why volume is so high:
Incomplete onboarding: Users provisioned with 80% of needed access, request the missing 20% over first weeks.
No self-service: Users cannot browse app catalog and request access themselves. Must create ticket for IT to process.
No role-based provisioning: Since access isn't role-based, many requests are for standard tools that should have been provisioned automatically.
Ad-hoc needs: User joins project, needs temporary app access for project duration.
Permission escalation: User needs higher permission level, must request upgrade.
The Processing Burden
Each access request ticket requires:
- IT reads ticket and understands request
- IT determines if request is legitimate (user actually needs this)
- IT identifies who should approve (manager? app owner? both?)
- IT routes to approver (email or ITSM workflow)
- IT waits for approval
- IT provisions access after approval
- IT notifies requester
- IT closes ticket
Time per ticket: 15-30 minutes depending on complexity
250 tickets/quarter × 20 minutes = 83 hours per quarter = 330 hours per year
Cost: 330 hours × $65/hr = $21,450 per year just processing access requests
The Approval Problem
Most access requests should require approval (security control, least privilege principle). But approval workflows at mid-market are broken.
How approval should work:
- User requests access
- System routes to appropriate approver
- Approver reviews and approves/denies
- System provisions automatically
- User notified
How approval actually works:
- User creates ticket
- IT emails approver
- Approver doesn't respond
- IT follows up
- Approver approves via email
- IT manually provisions
- IT manually notifies user
Why approvals fail:
No automated routing: IT must determine who should approve and email them manually.
Email-based approval: Approvals happen via email, which is:
- Easy to miss
- No SLA
- No audit trail
- Lost in inbox
No accountability: If approver doesn't respond, there's no escalation. Request just sits.
No context for approver: Approver receives: "Approve access to Salesforce for Sarah?" But approver doesn't know:
- Why Sarah needs access
- What Sarah will do with access
- What permission level is appropriate
- How long access is needed
So approver defaults to "approve" because denying requires investigation.
The "No Self-Service" Problem
Most mid-market companies have no self-service access request portal. Users must:
- Create ticket in ITSM (Jira, ServiceNow)
- Wait for IT to process
- Wait for approval
- Wait for provisioning
Total wait: 2-5 days
Why users hate this:
Need arises: "I need Figma to review this design"
- Create ticket: 5 minutes
- Wait for IT: 4 hours (next day in queue)
- Wait for approval: 24 hours (manager responds to email)
- Wait for provisioning: 2 hours (design team provisions)
Total time: 2 days
User needed Figma for a meeting that happened yesterday. By the time access is provisioned, the meeting is over.
The self-service ideal:
- User browses app catalog
- User clicks "Request access to Figma"
- System routes to manager for approval
- Manager approves in 1 click
- System provisions automatically (or creates task for app owner)
- User has access in 1 hour
This requires:
- App catalog (documentation of all available apps)
- Request workflow system
- Approval routing logic
- Integration with provisioning
Most mid-market companies have none of this. They have ITSM tools designed for break-fix support, not access workflows.
The Audit and Compliance Burden
Everything we've discussed so far creates technical and operational problems. But at mid-market scale, it also creates compliance problems that can block revenue.
Why Mid-Market Faces Enterprise Compliance Requirements
10 years ago, compliance frameworks like SOC 2 and ISO 27001 were enterprise concerns. Today, mid-market companies need them to sell to enterprise customers.
Enterprise procurement teams ask:
- "Are you SOC 2 certified?"
- "Can you provide evidence of access controls?"
- "How do you manage user lifecycle?"
Without answers, you don't get the contract.
So mid-market companies pursue compliance certifications despite lacking the tools and processes enterprises have.
Manual Access Reviews Are Unsustainable
SOC 2 and ISO 27001 require periodic access reviews (quarterly or annually). Reviewers must verify:
- All users have appropriate access
- Terminated employees have no access
- Least privilege is enforced
- High-privilege access is justified
At mid-market scale, this is a manual nightmare.
What access reviews require:
For each app:
- Pull list of all users and their permissions
- Cross-reference with current employees (identify terminated users who still have access)
- Send list to manager for each department: "Verify these people should have this access"
- Wait for manager responses
- Follow up with managers who don't respond
- Remediate any issues (remove inappropriate access)
- Document everything for auditors
For 50 apps, this is 50 manual user list pulls, 50 manager reviews, hundreds of email exchanges.
Time required:
500 employees, 50 apps = 25,000 user-app relationships to review (most employees don't use all apps, so actual number is lower, maybe 10,000)
Even at high efficiency:
- 2 minutes per user-app relationship to review
- 10,000 relationships = 333 hours per review
- Quarterly reviews: 333 hours × 4 = 1,332 hours per year = 67% of one FTE
Customer quote: "Teams spend days or weeks pulling user lists, checking app logs, emailing department heads, and generating evidence manually. This is slow and error-prone. For ISO 27001, this becomes a recurring burden."
The manager burden:
Managers receive spreadsheets: "Review these 50 people and verify their Salesforce access is appropriate."
Managers don't actually know:
- What permission each person has (spreadsheet might say "User" but what does that mean?)
- What tasks each person does that require this access
- Whether the person actually uses the app
So managers default to "looks fine" because actually investigating would take hours.
Result: Access reviews become checking the box for compliance without actually reviewing access quality.
No Audit Trail
Compliance frameworks require evidence that:
- Access was provisioned with proper approval
- Access was removed when people left
- Changes to access were authorized
Mid-market companies provisioning via email and Slack cannot produce this evidence.
What auditors ask for: "Show me evidence that Alex Chen's Salesforce access was approved by his manager before provisioning."
What mid-market companies have: Email thread from 2 years ago where manager said "yes give him Salesforce" buried in 10,000 other emails. Or worse, Slack message that has been archived and cannot be retrieved.
What auditors want:
- Timestamp of request
- Identity of requester
- Business justification
- Identity of approver
- Timestamp of approval
- Timestamp of provisioning
- Who performed provisioning
What mid-market companies can produce: "We're pretty sure we provisioned him correctly, the manager must have approved it, we don't have written evidence but trust us we wouldn't have provisioned without approval."
This doesn't satisfy auditors.
Audit preparation:
Without systematic audit trails, mid-market companies spend 2-4 weeks before each audit reconstructing evidence manually:
- Search emails for approval evidence
- Pull system logs to prove provisioning happened
- Cross-reference HRIS to prove user was employee at time of provisioning
- Create spreadsheets documenting evidence
- Compile screenshots
This is time-consuming, error-prone, and stressful. And if evidence cannot be found for certain provisioning actions, that's an audit finding.
"Why Do Terminated Users Still Have Accounts?"
This is the question auditors ask every quarter. And mid-market companies cannot answer it satisfactorily.
Customer quote: "Auditors ask: Why do terminated users still have visible accounts? This leads to compliance failures and repeated audit issues."
Auditor process:
- Pull list of users terminated in last 12 months from HRIS (150 users)
- Pull list of active users from 10 sampled apps
- Cross-reference: Which terminated users still show as "active" in apps?
- For each one found, ask: "Why is this person still active?"
What auditors find:
Testing of 25 terminated employees revealed:
- 18 (72%) still had active accounts in one or more systems 30+ days after termination
- 5 (20%) still had active licenses assigned
- 3 (12%) appeared to have logged in after termination (actually just account not disabled)
Finding: Controls over access termination are not operating effectively. Remediate immediately.
Why terminated users have active accounts:
Definition mismatch: IDP disabled the user (cannot log in via SSO). But the account still exists in the app. From IDP perspective: account disabled. From app perspective: account active.
70/30 coverage: IDP disabled SSO access. But 70% of apps aren't SSO. Those accounts never got disabled.
Manual offboarding incomplete: IT tried to manually remove from 50 apps. Forgot 10-15 apps. Those accounts remain.
Department-owned apps: IT notified department admins to remove access. Some didn't respond. Access remains.
This is a repeated finding every quarter. Mid-market companies remediate (spend weeks cleaning up), but next quarter the finding recurs because the process hasn't changed.
The Cost of Compliance Failures
Failed audits have real business consequences:
Delayed certifications: Cannot sell to enterprise customers until certification is granted. Delays revenue.
Remediation costs: Must fix all findings before re-audit. Weeks of IT time plus consultant fees.
Customer trust: Existing enterprise customers get nervous. "If you can't pass your audit, how can we trust you with our data?"
Insurance: Cyber insurance premiums increase or coverage denied without clean audits.
One customer described this: "Manual evidence collection is time-consuming and incomplete. We spend weeks compiling evidence, and auditors still find gaps. This delays our SOC 2 certification and blocks deals."
What Functional Provisioning Actually Looks Like
The goal isn't zero human involvement. The goal is systematic provisioning that scales linearly with headcount instead of exponentially with coordination overhead.
Here's what that means in practice:
1. HR Event Triggers Workflow Automatically
Instead of: HR creates ticket → IT reads ticket → IT emails manager → wait for response → IT provisions manually
Functional provisioning: HR creates employee in HRIS with start date → System detects new employee → System starts provisioning workflow automatically on schedule → System provisions based on role → System notifies stakeholders when complete
How this works:
- Day -7: Manager submits requisition in HRIS
- Day -5: HR creates employee record (name, title, department, start date = Day 0)
- Day -3: Provisioning system syncs from HRIS, sees new employee
- Day -3: System creates provisioning workflow:
- Route to IT for account creation
- Route to department admins for app provisioning
- Route to hiring manager for verification
- Schedule completion for Day -1 (day before start)
- Day -2: System executes provisioning:
- Creates Azure AD account (automated)
- Assigns M365 license (automated)
- Creates Slack account (automated)
- Adds to appropriate Slack channels based on department (automated)
- Creates tasks for department admins: "Provision Alex for Salesforce" (manual but tracked)
- Notifies hiring manager: "Alex's provisioning is 80% complete, missing Salesforce and GitHub"
- Day -1: Department admins complete their tasks
- Day 0: Alex starts work with full access
No tickets. No email chains. No manual coordination. System orchestrates the workflow.
2. Role-Based Access Is Enforced Systematically
Instead of: IT guesses what the person needs → gets it wrong → user requests missing access → inconsistent results
Functional provisioning: Role definitions exist → System applies role bundle → Exceptions require approval → Audit trail shows what was applied and why
How this works:
Company defines roles:
- Sales Development Rep = Salesforce (User), HubSpot (User), LinkedIn Sales Nav (User), Gong (User)
- Account Executive = Salesforce (Power User), HubSpot (User), ZoomInfo (User), Gong (User)
- Sales Engineer = Salesforce (User), GitHub (Read), AWS (View Only), Figma (Viewer)
When new Sales Engineer is hired:
- System sees role = "Sales Engineer"
- System provisions the role bundle automatically
- System documents: "Provisioned per Sales Engineer role policy v2.3"
- Audit trail exists: User got X access because of Y policy applied on Z date
If user needs exception (Sales Engineer needs different access):
- User or manager requests exception
- Exception requires justification and approval
- Exception is documented
- Audit trail shows: "Exception to policy, approved by [manager], reason: [working on special project requiring different tools]"
The question changes from "what does this person need" to "what role are they in." Provisioning becomes deterministic. Two people in the same role get identical access.
3. Department-Owned Apps Are Part of Orchestrated Workflow
Instead of: IT emails department admins → wait for responses → follow up manually → no visibility
Functional provisioning: System creates tasks for department admins → SLAs enforced → Central visibility → Audit trail
How this works:
New Sales Engineer needs:
- Apps IT controls: Azure AD, M365, Slack (automated by IT)
- Apps Sales controls: Salesforce (manual by Sales admin)
- Apps Engineering controls: GitHub, AWS (manual by Eng admin)
System orchestrates:
- IT apps provisioned automatically
- Task created for Sales admin: "Provision Alex Chen for Salesforce (User), due Day -1"
- Task created for Eng admin: "Provision Alex Chen for GitHub (platform-team read only), due Day -1"
- Dashboard shows: Overall provisioning 60% complete, 2 tasks pending
- Sales admin sees their task in dashboard, provisions Salesforce, marks complete
- Eng admin sees their task, provisions GitHub, marks complete
- IT sees: Provisioning 100% complete. Notifies Alex and manager.
Central visibility, distributed execution, systematic tracking.
4. Visibility Includes All Apps (Not Just SSO)
Instead of: IDP covers 30%, no visibility into 70%
Functional provisioning: Discovery shows all apps → User-app relationships visible centrally → Provisioning tasks created for all apps (even manual ones) → Central reporting
How this works:
System discovers:
- SSO apps via IDP (30%)
- Non-SSO apps via SSO logs, browser plugins, financial data, user surveys (70%)
Complete inventory:
- 50 apps total
- 15 apps have SSO + API (fully automated)
- 15 apps have SSO but no API (semi-automated: SSO for login, manual for provisioning)
- 20 apps have no SSO (fully manual)
For new hire provisioning:
- 15 SSO+API apps: Automated provisioning
- 15 SSO-only apps: System creates manual tasks for provisioning
- 20 no-SSO apps: System creates manual tasks
Even for manual apps, system tracks:
- Who should provision
- When provisioning happened
- Who completed it
- Audit trail
You cannot automate everything, but you can track everything. Central visibility means IT can answer: "Did Alex get provisioned for all 50 apps?" even if 30 of them were provisioned manually by 10 different department admins.
5. Rules Are Enforced by System, Not Memory
Instead of: Spreadsheet with 2,000 conditional rules → maintained manually → errors accumulate
Functional provisioning: Attribute-based rules defined once → System enforces automatically → Version controlled → New IT staff don't need to learn rules
How this works:
Rules defined as:
IF role = "Sales Engineer"
AND department = "Sales"
AND location = "US"
THEN provision:
- Salesforce (User)
- GitHub (Read, teams: platform-team, api-team)
- AWS (View Only, account: production-read-only)
System enforces:
- When new Sales Engineer hired → System applies rule automatically
- Rule stored in version control → Can track what changed and when
- Rule applied consistently → Every Sales Engineer gets identical access
- New IT staff don't need to memorize rules → System knows them
When business changes:
- Sales Engineers now need Figma access → Update rule
- Next Sales Engineer provisioned → Gets Figma automatically
- Existing Sales Engineers → System detects gap, offers to provision Figma for all
- Change documented: Rule v2.3 → Rule v2.4, added Figma, effective date X
Provisioning becomes deterministic and auditable.
6. Deprovisioning Is Comprehensive and Immediate
Instead of: Manual app-by-app deprovisioning → apps forgotten → orphaned accounts
Functional provisioning: System knows all apps user has → Deprovision workflow orchestrated → Comprehensive removal → Audit trail
How this works:
Alex leaves company (termination date = today)
System:
- Sees termination in HRIS (automatic sync)
- Identifies all apps Alex has access to (from centralized visibility)
- Creates deprovisioning workflow:
- Automated tasks: Disable Azure AD, remove from M365 groups, disable Slack
- Manual tasks: Remove from Salesforce (Sales admin), remove from GitHub (Eng admin), remove from 15 other apps
- Executes workflow:
- Automated tasks complete immediately
- Manual tasks assigned to appropriate admins with SLA
- Tracks completion
- Generates report: "Alex offboarded, 45 of 50 apps completed, 5 pending"
IT doesn't need to remember which apps Alex had. System knows. IT doesn't need to coordinate manually. System orchestrates.
Emergency offboarding:
IT can trigger immediate disable:
- Azure AD disabled NOW
- Slack disabled NOW
- Email disabled NOW
- VPN disabled NOW
- Automated tasks execute immediately
- Manual tasks escalated to admins with "URGENT" flag
Data transfer workflow:
- System prompts: "Alex left. Transfer files/email?"
- Manager selects: Transfer email to me, transfer Drive files to Sarah (team member)
- System creates tasks: Transfer Alex's email → Manager, Transfer Alex's files → Sarah
- Tasks executed and tracked
7. Role Changes Trigger Access Updates
Instead of: Role changes happen → access accumulates → privilege creep
Functional provisioning: Role change detected → System compares old role vs new role → Provisions new access → Removes old access → Audit trail
How this works:
Sarah changes role: Sales Rep → Sales Manager
System:
- Detects role change in HRIS (automatic sync)
- Compares access:
- Sales Rep role bundle: Salesforce (User), HubSpot (User), Sales Nav (User)
- Sales Manager role bundle: Salesforce (Manager), Gong (Admin), Team dashboards (User)
- Calculates changes:
- Add: Salesforce Manager upgrade, Gong Admin, Team dashboards
- Remove: Sales Nav (managers don't prospect)
- Keep: HubSpot
- Creates workflow:
- Provision new access
- Remove old access
- Notify Sarah and manager
- Executes and tracks
No accumulation. No privilege creep. Access adjusts to reflect current role, not historical roles.
8. Contractor Access Has Built-In Expiration
Instead of: Contractor access manually tracked → expires via calendar reminders → often forgotten
Functional provisioning: Contract end date in system → Access expires automatically → Notification before expiration → Manager can extend if needed
How this works:
Contractor hired for 3 months, contract end date = Day 90
System:
- Provisions access for contractor
- Sets expiration date = contract end date
- Day 80: Notifies manager: "Contractor Alex's access expires in 10 days. Extend contract?"
- Manager: "Contract extended to Day 120" → System updates expiration OR Manager: No response → Day 90: Access expires automatically
Temporary access enforced programmatically, not by memory.
Discovery First, Automation Second
Most mid-market companies approach provisioning backwards. They try to automate before understanding what they're automating.
The standard approach:
- Buy IDP (Okta, Azure AD)
- Integrate SSO apps
- Automate provisioning for SSO apps
- Realize 70% of apps aren't covered
- Continue manual provisioning for those apps
- Declare success on 30%, ignore 70%
This approach fails because:
- Doesn't solve the coordination problem (70% of apps still manual)
- Doesn't solve the inconsistency problem (no role-based access)
- Doesn't solve the audit problem (no trail for manual provisioning)
- Doesn't solve the visibility problem (don't know who has access to what)
The correct sequence:
Phase 1: Discover What Exists
Before automating anything, answer:
- What apps exist? (including non-SSO, shadow IT)
- Who has access to each app?
- What permission level does each person have?
- Which accounts are unused?
- Which accounts belong to terminated employees?
This requires discovery tools that can:
- Integrate with SSO logs (see what apps are accessed via SSO)
- Integrate with financial systems (see what apps are purchased)
- Integrate with browser usage (see what apps employees actually use)
- Integrate with individual apps via APIs (pull user lists)
Output: Complete inventory of apps and user-app relationships.
Phase 2: Define Policy Based on Reality
Look at actual access patterns:
- All Sales Reps have Salesforce, HubSpot, Sales Nav → This should be the Sales Rep role bundle
- Some Sales Reps have Gong, some don't → Should all Sales Reps have Gong? If not, why not?
- Some Engineers have prod access, some don't → What's the rule? Should Senior Engineers have it? Should all Engineers have it?
Defining policy isn't creating policy from scratch. It's codifying the patterns that already exist (and deciding which patterns are correct vs which are privilege creep).
Output: Role-based access policies that reflect actual business needs.
Phase 3: Remediate Gaps
Compare current access to desired policy:
- Who has too much access? (remove)
- Who has too little access? (provision)
- Which accounts are orphaned? (remove)
This is the cleanup phase. Before you can automate provisioning, you need current state to match desired state.
Output: Clean access state where everyone has appropriate access per policy.
Phase 4: Automate What Can Be Automated
Now that you know what apps exist and what access should look like:
- Automate provisioning for apps with APIs (30%)
- Create systematic workflows for apps without APIs (70%)
- Enforce role-based access automatically where possible
- Track manual provisioning systematically where automation isn't possible
Output: Provisioning that is partially automated, partially orchestrated, but fully tracked.
Phase 5: Maintain Over Time
As business changes:
- New apps adopted → Discover and add to inventory
- Roles change → Update policies
- People join/leave/move → Provisioning/deprovisioning happens per policy
- Access drift detected → Remediate automatically or alert for manual fix
The critical insight: You cannot automate provisioning until you know what to provision. And you cannot know what to provision until you discover what exists and codify what access should look like by role.
Most IGA vendors skip Phase 1-3 and jump to Phase 4. This is why they fail at mid-market: they assume you know your app inventory, you've defined policies, and you have clean access state. Mid-market companies have none of these.
Discovery must come first.
What This Means for You
If you're reading this and recognizing your current provisioning process, here's what matters:
Manual provisioning doesn't scale. The coordination overhead increases faster than headcount. At 500 employees, you're hitting the breaking point. At 1,000, it's unsustainable. The cost accumulates every quarter: $175K per year becoming $385K per year within 4 years as the company grows.
The cost isn't just time. It's:
- Security risk (inconsistent access, orphaned accounts, over-privileged users)
- Compliance gaps (no audit trail, failed access reviews, repeated audit findings)
- Productivity loss (new hires waiting days for access, employees blocked on access requests)
- Opportunity cost (IT doing manual coordination instead of strategic work)
- Employee experience (frustrating onboarding, slow response to requests)
Buying an IDP doesn't solve this. IDPs solve 30% of the problem (SSO apps) while leaving 70% (non-SSO apps) exactly as manual as before. The coordination burden, inconsistency, and audit gaps remain.
You don't need enterprise IGA budgets. But you need more than IDP + Slack + email. You need:
- Visibility into all apps (not just SSO)
- Role-based provisioning logic (not tribal knowledge in spreadsheets)
- Orchestrated workflows (not manual email coordination)
- Audit trails that satisfy SOC 2 auditors (not reconstructed after the fact)
Start with discovery. You cannot fix provisioning until you know:
- What apps exist
- Who has access to what
- What access should look like by role
- Where the gaps are
Attempting to solve provisioning without discovery is like trying to navigate without a map. You might get somewhere, but it won't be where you intended.
The companies that solve provisioning at mid-market scale aren't the ones with the most sophisticated automation. They're the ones who systematized provisioning first, then automated the systematized processes second.
That's the difference between scaling provisioning and scaling chaos.
The question isn't whether to fix provisioning. The question is whether to fix it now when it costs $175K per year, or later when it costs $385K per year and blocks revenue due to compliance failures.
Manual provisioning is technical debt. Like all technical debt, the interest compounds. Pay it down early, or pay far more later.
Frequently Asked Questions
What is user provisioning? User provisioning is the process of creating, managing, and removing user accounts across an organization's systems throughout the employment lifecycle—joiners (hire), movers (role change), leavers (exit). It manages whether a user exists in a system, not what they can do inside it. That's access provisioning—a distinct process most tools handle separately.
Why does manual user provisioning break at scale? Manual provisioning is a coordination problem. At 50 employees, one IT admin can manage it. At 300+, each hire requires coordinating across 5–15 stakeholders—HR, hiring managers, department app admins—who all have other jobs. Email chains get lost. Requests sit unanswered for days. Coordination overhead compounds faster than headcount. At 500 employees with 50 hires per quarter, the process creates permanent backlog, inconsistent setups, and security gaps.
What does manual user provisioning actually cost? For an 800-person company running 200 hires per year: approximately $175,000 annually. Direct IT labor: $26,000. Hiring manager coordination: $7,500. New hire productivity loss (average one day blocked waiting for access): $100,000. Compliance overhead: $11,000. Growing at 30% annually, the same company hits $385,000 by year four. Manual provisioning is technical debt that compounds with headcount.
What is JML and why does it matter? JML stands for joiner, mover, leaver—the three lifecycle events that drive provisioning. Joiners require creating accounts. Movers require updating access when roles change—adding new, removing old. Leavers require revoking everything. Most companies automate joiners partially, handle movers reactively, and execute leavers inconsistently. Movers are the most neglected: access from old roles accumulates indefinitely, which is how engineers end up with Salesforce admin access two years after leaving the sales team.
What is birthright access? Birthright access is the set of accounts granted automatically on hire based on role and department—no request, no approval required. A new Platform Engineer gets GitHub, Jira, and AWS on Day 1. A new Account Executive gets Salesforce, HubSpot, and Gong. Without it, IT guesses based on tribal knowledge, copying access from whoever was hired before—inconsistent, error-prone, unauditable. If more than 30% of new hires request missing access in week one, birthright policies are too narrow.
What is privilege creep? Privilege creep is access accumulation from role changes that add permissions without removing old ones. A sales rep who moves to customer success gets Zendesk provisioned—but keeps Salesforce admin and LinkedIn Sales Navigator. After three role changes, the person holds access from every position they've ever had. It happens through organizational amnesia: role changes add access urgently, remove access never—because the person isn't blocked and there's no escalation pressure.
Why do orphaned accounts accumulate after offboarding? Because IT disables the identity provider account—which cuts SSO access—but 70% of apps aren't SSO-integrated. Those accounts stay active: credentials still work, licenses still assigned. A 500-person company running 150 terminations per year accumulates 3,000+ orphaned accounts annually. After three years: 9,000 accounts. Each is a security exposure, a wasted license, and a recurring audit finding.
How should emergency offboarding work differently? Standard offboarding can run over 24–48 hours. Emergency offboarding—involuntary termination, suspected data theft—needs to happen in minutes. The window between termination decision and account revocation is live security exposure. Emergency offboarding requires a single trigger that immediately kills IDP access, VPN, email, and Slack in parallel—without waiting for department admins. Most mid-market companies run the same serial manual process for both scenarios.
Why don't role changes trigger access updates? Three reasons: visibility (IT can't remove what they can't see across 50 apps), priority (the person isn't blocked so there's no urgency), and ownership (department-owned apps require two rounds of coordination—add and remove—per role change). The result: role changes reliably add access, almost never remove it.
What risk do contractor accounts create? Contractors get the same application access as employees for their project scope—including GitHub and AWS. But contract end dates live in procurement systems, not IT's provisioning workflow. Managers assume offboarding happens automatically. It doesn't. With 50 active contractors on 4-month cycles, a company runs 120 contractor offboardings per year. If 90% are missed, that's 108 ex-contractors with active credentials—no longer bound by any employment agreement.
What does a SOC 2 auditor look for in user provisioning? Evidence that access was approved before provisioning, revoked within SLA after termination, and reviewed quarterly. What auditors want: HRIS timestamps, corresponding provisioning actions, manager approval records, access review documentation. What most mid-market companies have: email threads, Slack messages, and spreadsheets that don't match any application's current state. Reconstructing this before each audit costs 2–4 weeks of IT time—and still produces gaps.
What is the right sequence to fix user provisioning? Visibility before automation. First: discover what apps exist and who has access to what. Second: codify observed patterns into birthright role bundles. Third: remediate current state (remove what shouldn't be there, provision what's missing). Fourth: automate the clean process. Companies that skip to automation build it on a broken foundation—provisioning the wrong access faster, at scale.



.svg)














